AI代理
工具評估
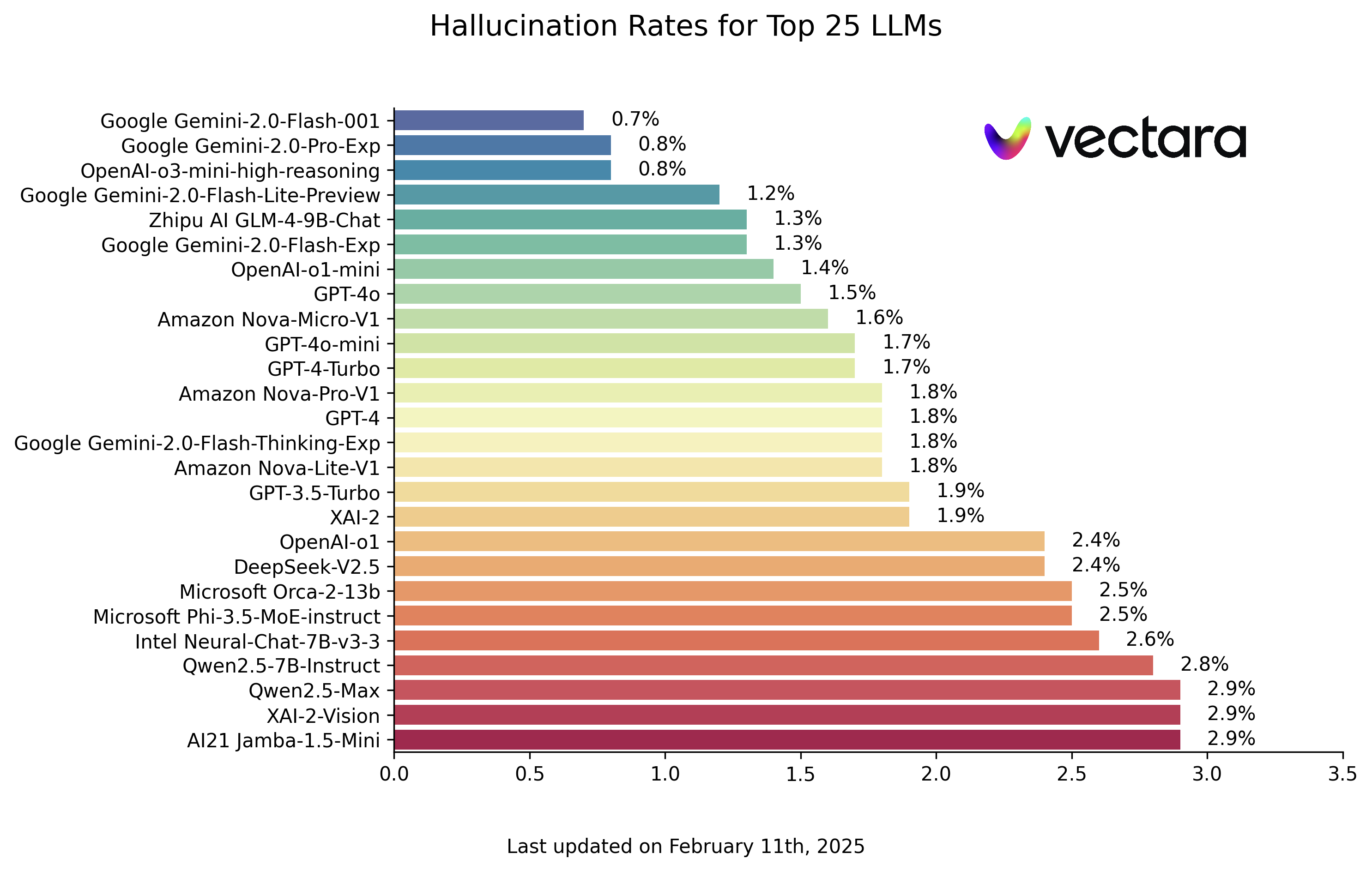
AI代理工具評估排行榜:Gemini-2.0-flash奪冠
Galileo Labs最新發布的AI代理工具評估排行榜顯示,Google的Gemini-2.0-flash以0.938的優異成績領先群雄。這項評估涵蓋了17個主流大型語言模型,測試其在實際業務場景中的工具使用能力。
圖:2024年2月AI代理工具評估排行榜(來源:Galileo Labs)
排行榜前五名分別為Gemini-2.0-flash(0.938)、GPT-4o(0.900)、Gemini-1.5-flash(0.895)、Gemini-1.5-pro(0.885)和o1(0.876)。評估框架包含了單輪對話、工具選擇、並行執行、錯誤處理等多個維度,全面反映了各模型在實際應用場景中的表現。
這項研究對AI開發者具有重要參考價值,特別是在選擇適合特定業務場景的模型時。研究團隊也開源了評估數據集,讓開發者能夠進行自主評估。